Web页面运行在各种各样的浏览器当中,浏览器载入、渲染页面的速度直接影响着用户体验 简单地说,页面渲染就是浏览器将html代码根据CSS定义的规则显示在浏览器窗口中的这个过程。先来大致了解一下浏览器都是怎么干活的:
1.用户输入网址(假设是个html页面,并且是第一次访问),浏览器向服务器发出请求,服务器返回html文件;
2.浏览器开始载入html代码,发现<head>标签内有一个<link>标签引用外部CSS文件;
3.浏览器又发出CSS文件的请求,服务器返回这个CSS文件;
4.浏览器继续载入html中<body>部分的代码,并且CSS文件已经拿到手了,可以开始渲染页面了;
5.浏览器在代码中发现一个<img>标签引用了一张图片,向服务器发出请求。此时浏览器不会等到图片下载完,而是继续渲染后面的代码;
- 服务器返回图片文件,由于图片占用了一定面积,影响了后面段落的排布,因此浏览器需要回过头来重新渲染这部分代码;
7.浏览器发现了一个包含一行Javascript代码的<script>标签,赶快运行它; - Javascript脚本执行了这条语句,它命令浏览器隐藏掉代码中的某个<div> (style.display=”none”)。杯具啊,突然就少了这么一个元素,浏览器不得不重新渲染这部分代码;
- 终于等到了</html>的到来,浏览器泪流满面……
- 等等,还没完,用户点了一下界面中的“换肤”按钮,Javascript让浏览器换了一下<link>标签的CSS路径 ; 11.浏览器召集了在座的各位<div><span><ul><li>们,“大伙儿收拾收拾行李,咱得重新来过……”,浏览器向服务器请
求了新的CSS文件,重新渲染页面。
浏览器每天就这么来来回回跑着,要知道不同的人写出来的html和css代码质量参差不齐,说不定哪天跑着跑着就挂掉了。好在这个世界还有这么一群人——页面重构工程师,平时挺不起眼,也就帮视觉设计师们切切图啊改改字,其实背地里还是干了不少实事的。
说到页面为什么会慢?那是因为浏览器要花时间、花精力去渲染,尤其是当它发现某个部分发生了点变化影响了布局,需要倒回去重新渲染**,内行称这个回退的过程叫reflow。**

reflow几乎是无法避免的
现在界面上流行的一些效果,比如树状目录的折叠、展开(实质上是元素的显示与隐藏)等,都将引起浏览器的 reflow。鼠标滑过、点击……只要这些行为引起了页面上某些元素的占位面积、定位方式、边距等属性的变化,都会引起它内部、周围甚至整个页面的重新渲染。通常我们都无法预估浏览器到底会reflow哪一部分的代码,它们都彼此相互影响着。
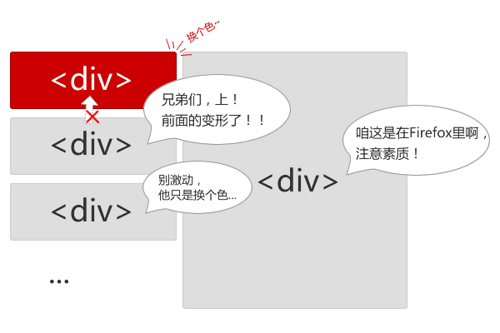
reflow问题是可以优化的,我们可以尽量减少不必要的reflow。比如开头的例子中的<img>图片载入问题,这其实就是一个可以避免的reflow——给图片设置宽度和高度就可以了。这样浏览器就知道了图片的占位面积,在载入图片前就预留好了位置。
另外,有个和reflow看上去差不多的术语:repaint,中文叫重绘。如果只是改变某个元素的背景色、文字颜色、边框颜色等等不影响它周围或内部布局的属性,将只会引起浏览器repaint。repaint的速度明显快于reflow(在IE下需要换一下说法,reflow要比repaint 更缓慢)。下次将通过一系列的实验说明在Firefox、IE等浏览器下reflow的优化。
从浏览器的渲染原理讲CSS性能
渲染引擎 Rendering Engine(也叫做排版引擎),也就是我们通常所说的“浏览器内核”,负责解析网页语法(如HTML、JavaScript)并渲染、展示网页。相同的代码在不同的浏览器呈现出来的效果不一样,那么就很有可能是不同的浏览器内核导致的。
下面看一下加载页面时浏览器的具体工作流程(图一):

1、解析HTML以重建DOM树(Parsing HTML to construct the DOM tree ):渲染引擎开始解析HTML文档,转换树中的标签到DOM节点,它被称为“内容树”。
2、构建渲染树(Render tree construction):解析CSS(包括外部CSS文件和样式元素),根据CSS选择器计算出节点的样式,创建另一个树 —- 渲染树。
3、布局渲染树(Layout of the render tree): 从根节点递归调用,计算每一个元素的大小、位置等,给每个节点所应该出现在屏幕上的精确坐标。
4、绘制渲染树(Painting the render tree) : 遍历渲染树,每个节点将使用UI后端层来绘制。主要的流程就是:构建一个dom树,页面要显示的各元素都会创建到这个dom树当中,每当一个新元素加入到这个dom树当中,浏览器便会通过css引擎查遍css样式表,找到符合该元素的样式规则应用到这个元素上。
注意了:css引擎查找样式表,对每条规则都按从右到左的顺序去匹配。 看如下规则:
#nav li {}
看起来很快,实际上很慢,尽管这让人有点费解#_#。我们中的大多数人,尤其是那些从左到右阅读的人,可能猜想浏览器也是执行从 左到右匹配规则的,因此会推测这条规则的开销并不高。在脑海中,我们想象浏览器会像这样工作:找到唯一的ID为nav的元素,然后把这个样式应用到直系子 元素的li元素上。我们知道有一个ID为nav的元素,并且它只有几个Li子元素,所以这个CSS选择符应该相当高效。
事实上,CSS选择符是从右到左进行匹配的。了解这方面的知识后,我们知道这个之前看似高效地规则实际开销相当高,浏览器必须遍历页面上每个li元素并确定其父元素的id是否为nav。
*{}
额,这种方法我刚写CSS的也写过,殊不知这种效率是差到极点的做法,因为*通配符将匹配所有元素,所以浏览器必须去遍历每一个元素,这样的计算次数可能是上万次!
ul#nav{} ul.nav{}
在页面中一个指定的ID只能对应一个元素,所以没有必要添加额外的限定符,而且这会使它更低效。同时也不要用具体的标签限定类选择符,而是要根据实际的情况对类名进行扩展。例如把ul.nav改成.main_nav更好。
ul li li li .nav_item{}
对于这样的选择器,之前也写过,最后自己也数不过来有多少后代选择器了,何不用一个类来关联最后的标签元素,如.extra_navitem,这样只需要匹配class为extra_navitem的元素,效率明显提升了对此,在CSS书写过程中,总结出如下性能提升的方案:
- 避免使用通配规则 如 *{} 计算次数惊人!只对需要用到的元素进行选择
- 尽量少的去对标签进行选择,而是用class 如:#nav li{},可以为li加上nav_item的类名,如下选择.nav_item{}
- 不要去用标签限定ID或者类选择符 如:ul#nav,应该简化为#nav
- 尽量少的去使用后代选择器,降低选择器的权重值后代选择器的开销是最高的,尽量将选择器的深度降到最低,最高不要超过三层,更多的使用类来关联每一个标签元素
- 考虑继承 了解哪些属性是可以通过继承而来的,然后避免对这些属性重复指定规则
选用高效的选择符,可以减少页面的渲染时间,从而有效的提升用户体验(页面越快,用户当然越喜欢^_^),这个实验的重点是评估复杂选择符和简单选择符的开销。也许当你想让渲染速度最高效时,你可能会给每个独立的标签配置一个ID,然后用这些ID写样式。那的确会超级快,也超级荒唐!这样的结果是语义极差,后期的维护难到了极点。
但说到底,CSS性能这东西对于小的项目来讲可能真的是微乎其微的东西,提升可能也不是很明显,但对于大型的项目肯定是有帮助的。而且一个好的CSS书写习惯和方式能够帮助我们更加严谨的要求自己。